Delete Backups
Portworx Backup allows you to either delete a single backup or multiple backups to provide flexibility in managing storage resources and keeping backup environments clean.
Deletion of single backup
When a specific backup is no longer needed, you can delete it individually. This is particularly useful for removing outdated or unnecessary backups while retaining others, saving storage space and costs without disrupting your backup strategy.
Deletion of multiple backups
When you want to delete multiple backups or perform a batch deletion task, Portworx Backup's concurrent or parallel deletion process enables efficient and simultaneous deletion of multiple backups and their associated volume and resources content. This enhancement ensures that dependencies, like incremental backups, are managed correctly, allowing for a streamlined and reliable cleanup process.
Parallel deletion of multiple backups with their volumes and resources reduces overall deletion time. Thread configurations allow users to tune the deletion process to suit their environment and resource availability. In environments where large numbers of backups need to be deleted quickly, this functionality allows for concurrent processing, saving time.
You can delete multiple backups in parallel, improving the efficiency of the deletion process. By default, five backups are selected for deletion at a time, with each backup deletion process spawning five threads for the deletion of associated volumes and resources.
Workflow
Classic mode
When a user deletes a backup in Classic mode, Portworx Backup coordinates with Stork and Portworx Enterprise to safely remove the backup data and associated metadata:
- Delete Initiation — When the user deletes a backup from the web console, CLI, or API, Portworx Backup marks the backup as Deleting.
- Deletion processing — Backups are processed in small batches (up to 5 at a time), with each backup processing up to 5 volume threads concurrently.
- Dependency checks — The system checks whether the backup contains Portworx volumes and whether dependent incremental backups exist. If incremental dependencies are detected, the dependent backups transition to the Delete Pending state until the dependencies are resolved.
- Backup removal — After no dependent incremental backups remain, Portworx Backup deletes the backup data and associated metadata from the backup location.
Federated mode
When a user deletes a backup in Federated mode, Portworx Backup coordinates with Stork and Portworx Enterprise across clusters to safely remove the backup metadata and underlying volume data from object storage:
- Delete Initiation — When the user deletes a backup from the web console, CLI, or API, Portworx Backup marks the backup as Deleting and creates a deletion request on the application cluster where the backup was created.
- Deletion processing — Stork running on the application cluster processes the deletion request. To avoid overwhelming the system, backups are processed in small batches (up to 5 at a time), while corresponding volumes are processed in batches of up to 10 concurrently.
- Stork offloads to Portworx Enterprise — Stork offloads the deletion to Portworx Enterprise, which removes the backup entry from the Portworx Backup catalog. Portworx Enterprise then performs dependency checks and deletes the associated volume snapshots from cloud storage.
- Backup removal — After all volume snapshots are deleted, Stork removes the backup metadata files from the object store, completing the cleanup.
Backup deletion time depends on the number of volumes, object store latency, and current cluster load. Large backups with many volumes may take several minutes to delete completely.
Thread configuration
Thread configuration for backup deletion differs between Classic mode and Federated mode.
Classic mode
In Classic mode, you can adjust the number of concurrent deletion jobs or volume threads by updating the px-backup deployment specification through the Helm chart.
pxbackup.backupDeleteWorker defines the maximum number of backups to be processed concurrently for deletion. The default value is 5.
pxbackup.volDeleteWorker defines the maximum number of threads assigned per backup to handle volume deletion. The default value is 5.
Previously, you updated configurations by directly editing Deployment manifests. Starting with the 2.10 release, manage these changes through Helm. If you previously modified a Deployment manifest directly, add the corresponding values to values.yaml when you upgrade to the new version.
Federated mode
In Federated mode, backup deletion is handled locally by Stork on each application cluster.
Setting Classic mode values during a fresh install
If you want to change these values from the default value of 5 to your desired values, set them in the values.yaml file provided during installation, or provide Helm options during installation.
helm install <release-name> portworx/px-central --namespace <namespace> --create-namespace --version <version> --set pxbackup.backupDeleteWorker=<new_value> --set pxbackup.volDeleteWorker=<new_value>
Or provide the following parameters in values-px-central.yaml:
pxbackup:
backupDeleteWorker: <new-value>
enabled: true
volDeleteWorker: <new-value>
helm install <release-name> portworx/px-central --namespace <namespace> --create-namespace --version <version> -f values-px-central.yaml
Updating Classic mode values after px-backup installation
If these values are not set during installation and you want to update them after installation, do the following:
- Extract the current values.yaml file used during installation.
helm get values --namespace <pxb-namespace> <release-name> -o yaml > values-current.yaml
- Update the values-current.yaml file with the following:
pxbackup:
backupDeleteWorker: <new-value>
enabled: true
volDeleteWorker: <new-value>
- Run the Helm upgrade:
helm upgrade <release-name> portworx/px-central \
--namespace <namespace> -f values-current.yaml
During an upgrade, ensure you always pass the current values.yaml file to retain the set parameter values. Helm upgrade will overwrite the values if the current values.yaml file is not provided.
Deletion states
Deleting state: Once a user initiates a deletion action (either through the web console or API), the backup enters the Deleting state. This state signals that the deletion process has been requested and that the backup is now eligible for further processing by the delete threads. The Deleting state indicates that the backup is in the queue for deletion.
Delete Pending state: After a delete thread picks up a backup for deletion, if any volumes and resources associated with the backup belong to Portworx Enterprise, the system performs a check for dependent incremental backups. If such dependencies are found (for example, incremental backups that rely on the backup being deleted), these dependent backups are moved to the Delete Pending state. This state indicates that there are other backups that must be deleted before the primary backup can be deleted. This ensures that the system maintains the integrity of incremental backup chains, preventing data loss from accidental or early deletions.
Dependency management
The system automatically scans for dependent backups, particularly in the case of incremental backups, ensuring that backup chains remain intact. A backup which is being deleted goes to Delete Pending state, if there exists another incremental backup which is dependent on the current backup being deleted.
For example, consider an incremental backup (IB) with incr =5, which means 5 incremental backups are created between each full backup (FB) and retain = 6, where 6 backups (1 full + 5 incremental) are retained before deletion is triggered.
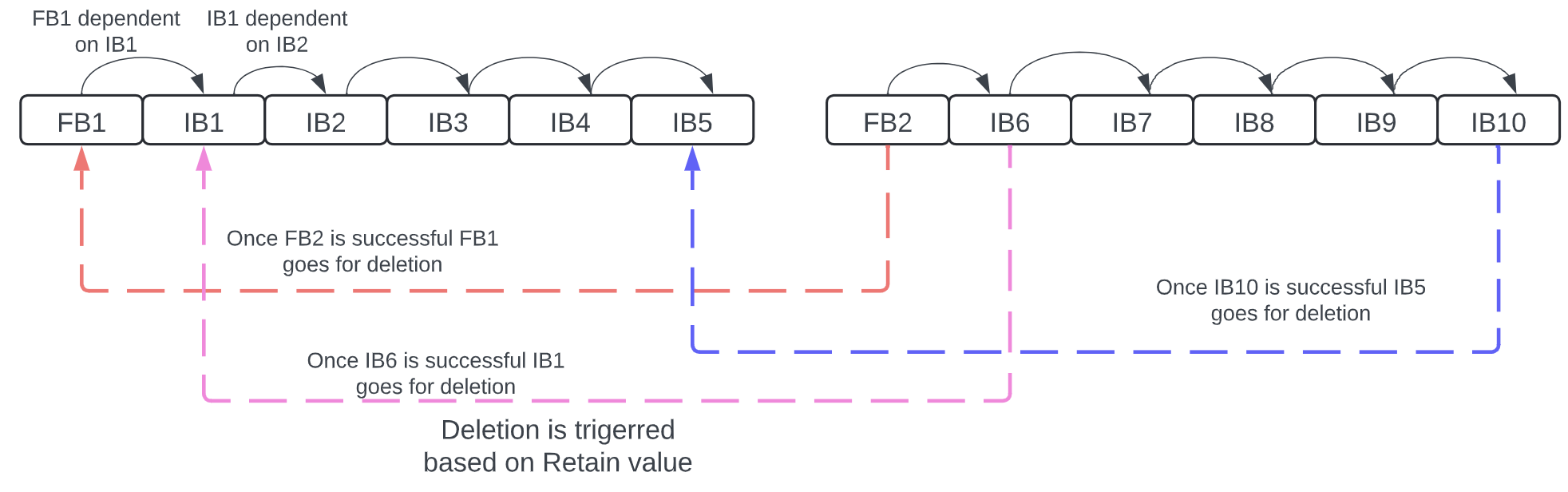
After FB2 (Full backup 2) is successfully created, FB1 is marked for deletion, and after IB6 (Incremental backup 6) is successful, IB1 can be deleted. After IB10 is successful, IB5 is also marked for deletion, with the strategy to retain the most recent backups and deleting the older ones.
- Dependency management is applicable only for Portworx volumes and not for other storage provisioners.
- Parallel deletes are not supported for NFS-backups. In other words, backups taken on NFS backup locations should be deleted serially (one-by-one).
How to delete backup(s)
Perform the following steps to delete backup(s) through Portworx Backup web console:
-
Access Portworx Backup web console with valid and active user credentials.
-
From the home page, click Clusters.
-
On the Clusters page, select the cluster that contains the backups you wish to delete.
-
Navigate to Backups tab and select the backups you want to delete:
-
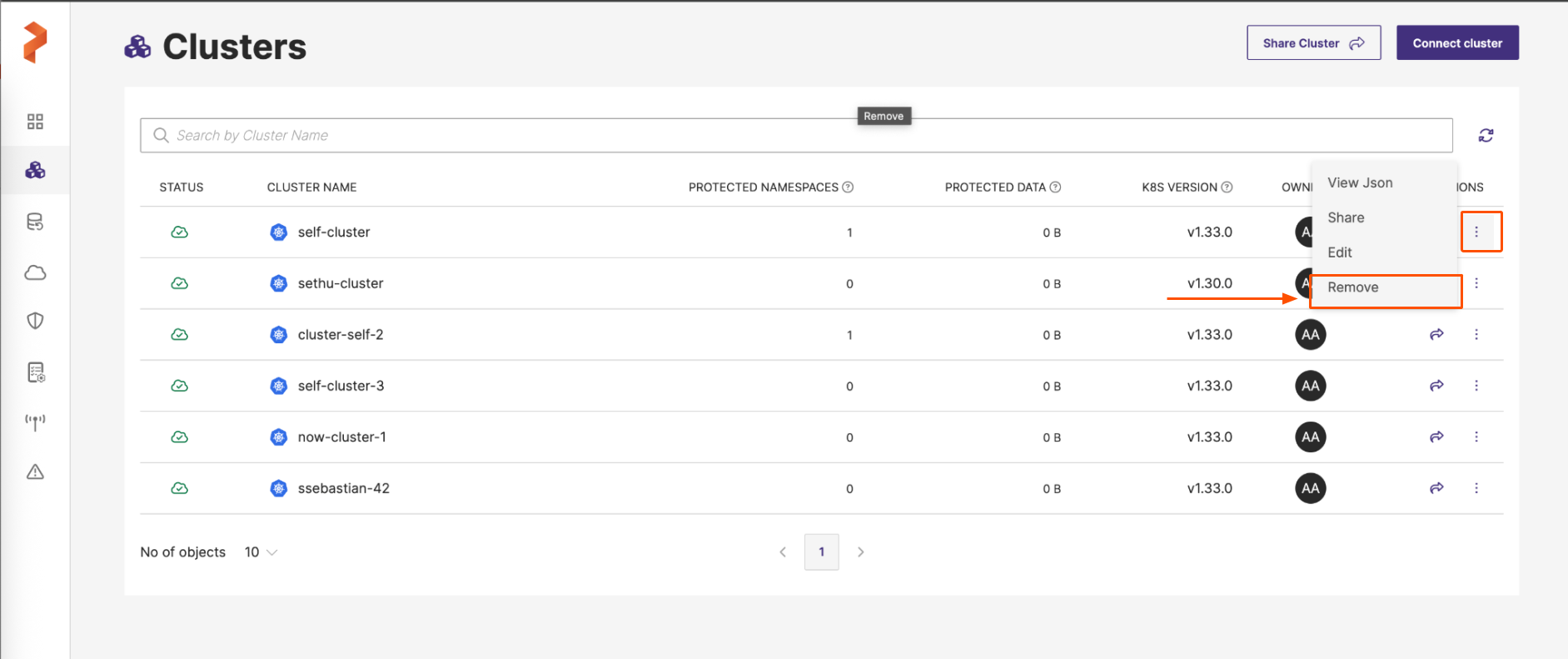
To delete a single backup, select the backup and move the cursor towards the Vertical ellipsis (vertically aligned three dots) next to the backup entry and choose Remove.
-
In case you want to delete multiple backups in a page, select the required backups, move the cursor towards the Vertical ellipsis next to any backup entry and choose Remove.
-
If you want to delete all backups of the page, click the Select All check box in the header row (under NS) tab to select all displayed backups. Click the Vertical ellipsis (three dots) next to any backup entry and choose Remove.
Result: The selected backup(s) are deleted after some time.
-
For information about force deleting backups when a shoot cluster is unreachable in Federated mode, see Force Delete Backups.