Manage storage nodes on VMware vSphere
This guide explains how the Portworx Dynamic Disk Provisioning feature works within Kubernetes on VMware and the requirements for it.
Installation steps below are only supported if you are running with Kubernetes.
Architecture
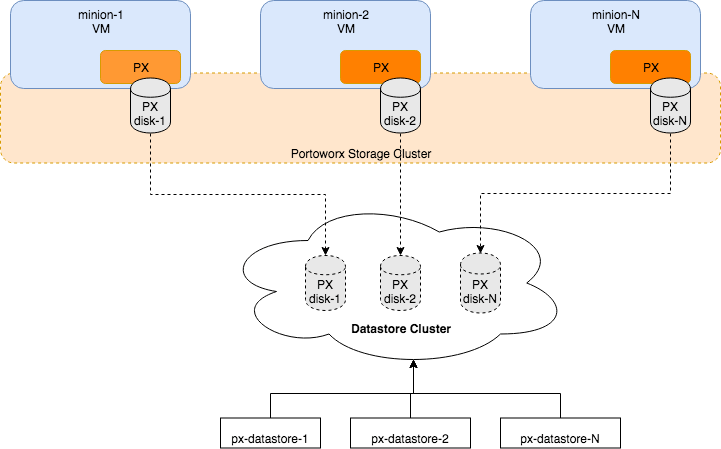
The following diagram gives an overview of the Portworx architecture on vSphere using shared datastores.
- Portworx runs on each Kubernetes minion/worker.
- Based on the given spec by the end user, Portworx on each node will create its disk on the configured shared datastores or datastore clusters.
- Portworx will aggregate all of the disks and form a single storage cluster. End users can carve PVCs (Persistent Volume Claims), PVs (Persistent Volumes) and Snapshots from this storage cluster.
- Portworx tracks and manages the disks that it creates. In a failure event, if a new VM spins up, Portworx on the new VM will be able to attach to the same disk that was previously created by the node on the failed VM.
Limiting storage nodes
Portworx allows you to create a heterogenous cluster where some of the nodes are storage nodes and rest of them are storageless.
You can specify the number of storage nodes in your cluster by setting the max_storage_nodes_per_zone input argument.
This instructs Portworx to limit the number of storage nodes in one zone to the value specified in max_storage_nodes_per_zone argument. The total number of storage nodes in your cluster will be:
Total Storage Nodes = (Num of Zones) * max_storage_nodes_per_zone
While planning capacity for your auto scaling cluster make sure the minimum size of your cluster is equal to the total number of storage nodes in Portworx. This ensures that when you scale up your cluster, only storageless nodes will be added. While when you scale down the cluster, it will scale to the minimum size which ensures that all Portworx storage nodes are online and available.
You can always ignore the max_storage_nodes_per_zone argument. When you scale up the cluster, the new nodes will also be storage nodes but while scaling down you will lose storage nodes causing Portworx to lose quorum.
Examples:
"-s", "type=lazyzeroedthick,size=200", "-max_storage_nodes_per_zone", "1"
For a cluster of 6 nodes spanning 3 zones (zone-1a,zone-1b,zone-1c), in the above example Portworx will have 3 storage nodes (one in each zone) and 3 storageless nodes. Portworx will create a total 3 disks of size 200 each and attach one disk to each storage node.
"-s", "type=lazyzeroedthick,size=200", "-s", "type=lazyzeroedthick,size=100", "-max_storage_nodes_per_zone", "2"
For a cluster of 9 nodes spanning 2 zones (zone-1a,zone-1b), in the above example Portworx will have 4 storage nodes and 5 storageless nodes. Portworx will create a total of 8 disks (4 of size 200 and 4 of size 100). Portworx will attach a set of 2 disks (one of size 200 and one of size 100) to each of the 4 storage nodes.
Availability across failure domains
Since Portworx is a storage overlay that automatically replicates your data, Portworx by Pure Storage recommends using multiple availability zones when creating your VMware vSphere based cluster. Portworx automatically detects regions and zones that are populated using known Kubernetes node labels. You can also label nodes with custom labels to inform Portworx about region, zones and racks. Refer to the Cluster Topology awareness page for more details.