Common errors in GKE
Failed to apply spec due Forbidden: may not be used when type is ClusterIP
If you had an older version of Portworx manifests installed, and you try to apply the latest manifests, you might see the following error during kubectl apply.
Service "portworx-service" is invalid: [spec.ports[0].nodePort: Forbidden: may not be used when `type` is 'ClusterIP', spec.ports[1].nodePort: Forbidden: may not be used when `type` is 'ClusterIP', spec.ports[2].nodePort: Forbidden: may not be used when `type` is 'ClusterIP', spec.ports[3].nodePort: Forbidden: may not be used when `type` is 'ClusterIP']
Error from server (Invalid): error when applying patch:
To fix this:
-
Change the type of the
portworx-serviceservice to type ClusterIP. If the type was NodePort, you will also have to remove the nodePort entries from the spec.kubectl edit service portworx-service -n <px-namespace> -
Change the type of the
portworx-apiservice to type ClusterIP. If the type was NodePort, you will also have to remove the nodePort entries from the spec.kubectl edit service portworx-api -n <px-namespace> -
Reapply your specs.
Failed DNS resolution
If you encounter the following error:
Jan 18 12:48:03 node1 portworx[872]: level=error msg="error in obtaining etcd version: \
Get http://_some_host:2379/version: dial tcp: lookup _some_host on [::1]:53: dial udp \
[::1]:53: connect: no route to host"
Please ensure that the NetworkManager service has been stopped and disabled on your Linux host system.
Cause
The Portworx processes running inside the OCI container must be able to perform the DNS hostname resolution, especially if using hostnames for KVDB configuration, or the CloudSnap feature. However, host's NetworkManager service can update the DNS configuration (the /etc/resolv.conf file) after the Portworx container has started, and such changes will not propagate from host to container.
Failure to install Portworx on SELinux
You may have experienced the following issue installing Portworx (e.g. Fedora 28 host)
# sudo docker run --entrypoint /runc-entry-point.sh --rm -i --name px-installer --privileged=true \
-v /etc/pwx:/etc/pwx -v /opt/pwx:/opt/pwx portworx/px-base-enterprise:2.1.2
docker: Error response from daemon: OCI runtime create failed: container_linux.go:345: starting \
container process caused "process_linux.go:430: container init caused \
\"write /proc/self/attr/keycreate: permission denied\"": unknown.
Cause
This error is caused by a Docker issue (see moby#39109), which prevents Docker from running even the simplest containers:
# sudo docker run --rm -it hello-world
docker: Error response from daemon: OCI runtime create failed: container_linux.go:345: starting \
container process caused "process_linux.go:430: container init caused \
\"write /proc/self/attr/keycreate: permission denied\"": unknown.
To work around this issue, either turn off SELinux support, or make sure to use docker-package provided by the host's platform.
Failure to install Portworx on Kubernetes
You may experience the following issue deploying Portworx into Kubernetes:
...level=info msg="Locating my container handler"
...level=info msg="> Attempt to use Docker as container handler failed" \
error="/var/run/docker.sock not a socket-file"
...level=info msg="> Attempt to use ContainerD as container handler failed" \
error="Could not load container 134*: container \"134*\" in namespace \"k8s.io\": not found"
...level=info msg="> Attempt to use k8s-CRI as container handler failed" \
error="stat /var/run/crio/crio.sock: no such file or directory"
...level=error msg="Could not instantiate container client" \
error="Could not initialize container handler"
...level=error msg="Could not talk to Docker/Containerd/CRI - please ensure \
'/var/run/docker.sock', '/run/containerd/containerd.sock' or \
'/var/run/crio/crio.sock' are mounted"
Cause
In Kubernetes environments, Portworx installation starts by deploying OCI-Monitor Daemonset, which monitors and manages the Portworx service. In order to download, install and/or validate the Portworx service, the OCI-Monitor connects to the appropriate Kubernetes container runtime via socket-files that need to be mounted into the OCI-Monitor's POD.
Please inspect the Portworx spec, and ensure the appropriate socket-files/directories are mounted as volumes from the host-system into the Portworx POD. Alternatively, you can reinstall Portworx, or at minimum generate a new YAML-spec via the Portworx spec generator page in Portworx Central, and copy the volume-mounts into your Portworx spec.
Failed to attach volume, device exists
When using Dynatrace on your cluster, you may encounter the following volume attach error:
failed to attach volume: rpc error: code = Internal desc = failed to attach volume: Cannot attach volume <volume-id>, device exists
Cause
Dynatrace OneAgent, running on all worker nodes, opens a file handle on a Portworx internal path (/var/lib/osd/pxns). This prevents Portworx from detaching its volumes, causing issues when you try to reattach them.
You can correct this issue by instructing Dynatrace to skip monitoring Portworx internal mountpaths. Portworx can then cleanly detach and remove its block devices from the host.
Create Disk Exclusion Rules
Perform the following steps to create disk exclusion rules to instruct Dynatrace to skip Portworx mount paths and disks:
Create a disk exclusion Rule to skip Portworx mount paths
- In the Dynatrace menu, navigate to the Hosts page and select the host for which you want to create a disk exclusion rule.
- On the host overview page, select Settings.
- Select Disk options.
- From the Disk options page, make the following changes:
- Set Mount point path to “/var/lib/osd/pxns/*”.
- Set File system type to “*”
- Save your changes.
Create a disk exclusion rule to skip Portworx devices
- In the Dynatrace menu, go navigate to the Hosts page and select the host for which you want to create a disk exclusion rule.
- On the host overview page, select Settings.
- Select Disk options.
- From the Disk options page, make the following changes:
- Set Disk path to “/dev/pxd/pxd*”.
- Add another Disk path for “/dev/mapper/pxd-enc*”.
- Set File system type to “*”.
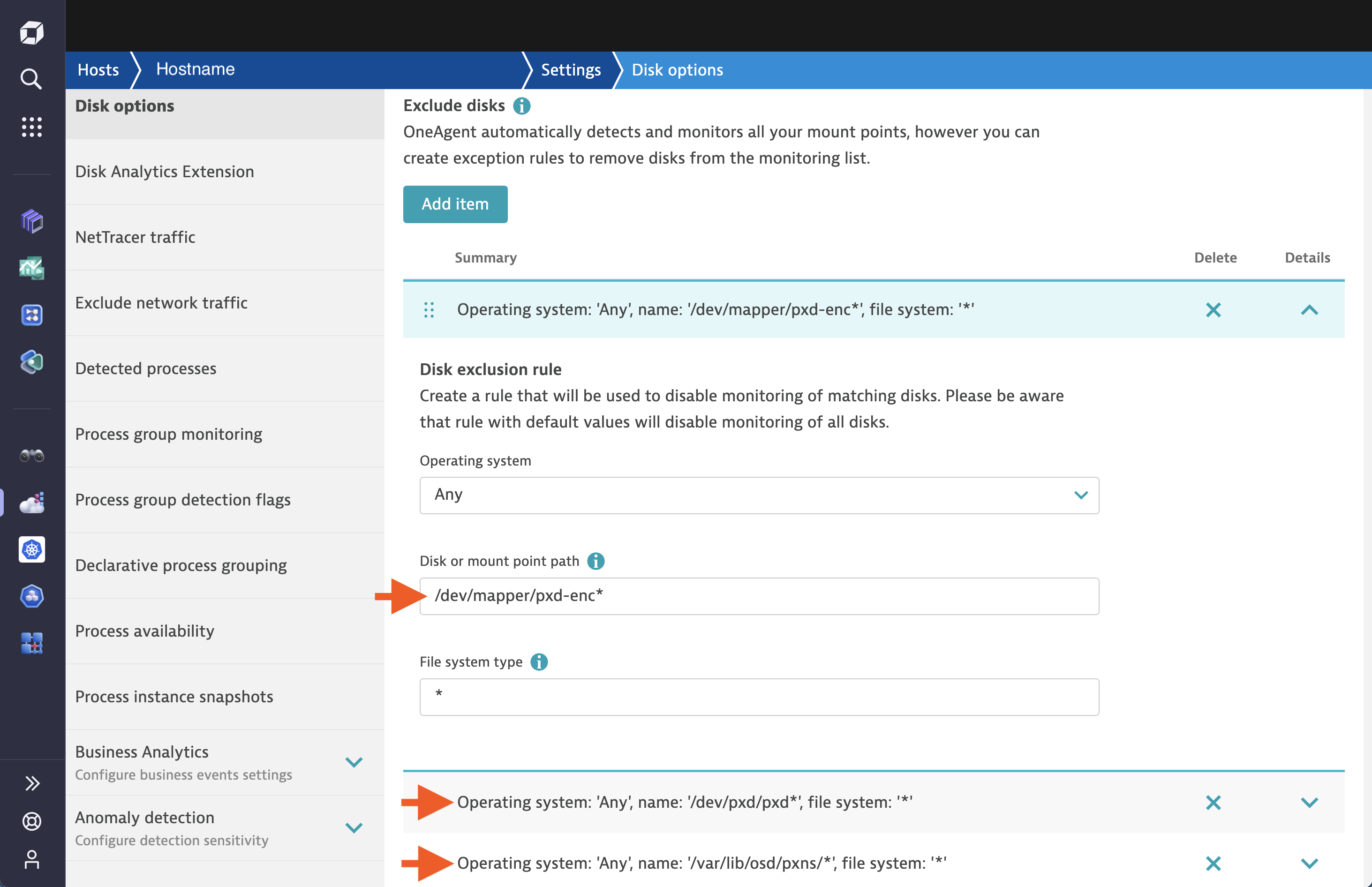
- Save your changes.
For more information, refer to the Dynatrace documentation.
Portworx installation failure on individual nodes
If installation failures are detected on specific nodes, run the following to restart Portworx on each of these nodes:
systemctl restart portworx
Portworx upgrade fails with the runc run failed error
During the upgrade process of Portworx, if you encounter failures with the following error in the log:
runc run failed: container with given ID already exists
Reboot the affected node for a successful upgrade of Portworx.
Same drive present in storage pools
When a drive within a storage pool goes offline and later comes back online, it may mistakenly appear as if it belongs to two different pools, with one pool showing as offline. This issue often arises due to changes in the order or naming of the drives or disks when drives that were previously offline are reconnected. To resolve this confusion and ensure your storage system operates correctly, follow these steps:
- Verify that all drives associated with the node are online.
- Perform a maintenance cycle to refresh the new drive name.