Deployment planning
There are 2 primary approaches you can take when architecting your Portworx deployment.
-
A) Disaggregated where the storage nodes are separate from the compute nodes
-
B) Converged where compute and storage nodes are the same
These two approaches are discussed below.
Approach A: Separate Storage and Compute clusters
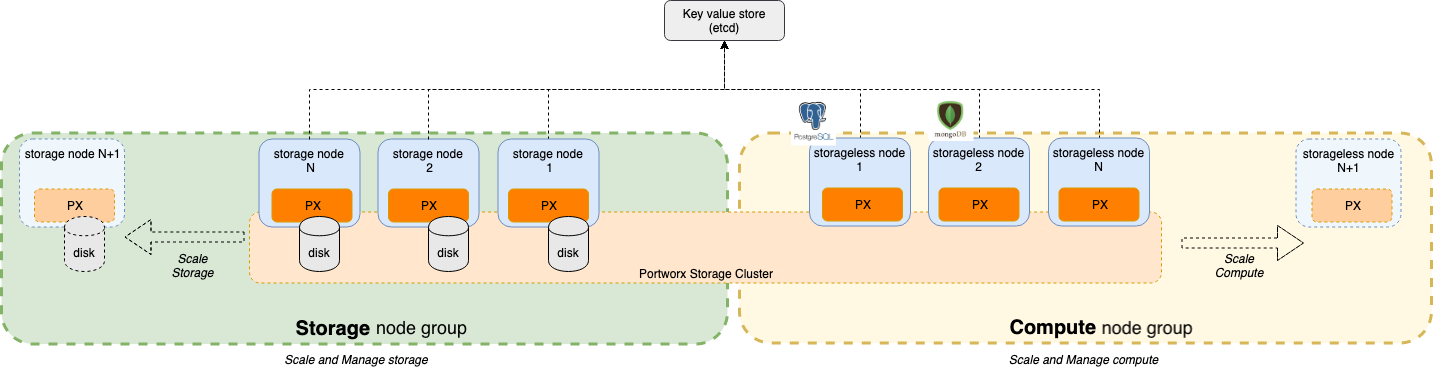
What
- Separate Storage node group (green above), Nodes in this node group have disks.
- Separate Compute node group (yellow above). The application container workloads run on these nodes.
- The Portworx installation (orange above) spans across both node groups to provide a single storage fabric.
- The Storage and Compute node groups are part of the same orchestrator cluster (Single Kubernetes cluster).
Why
You might choose to deploy using a disaggregated model if you have a very dynamic compute environment, where the number of compute nodes can elastically increase or decrease based on workload demand. Some examples of what can cause this elasticity are:
- Autoscaling up or down due to increasing and decreasing demands. An example would be to temporarily increase the number of worker nodes from 30 to 50 to handle the number of PODs in the system.
- Instance upgrades due to kernel updates, security patches etc
- Orchestrator upgrades (e.g Kubernetes upgrade)
Separating storage and compute clusters mean such scaling & management operations on the storage cluster don't interfere with the compute cluster, and vice versa.
Portworx by Pure Storage recommends this approach in autoscaling cloud environments.
Approach B: Hyperconverged Storage and Compute clusters
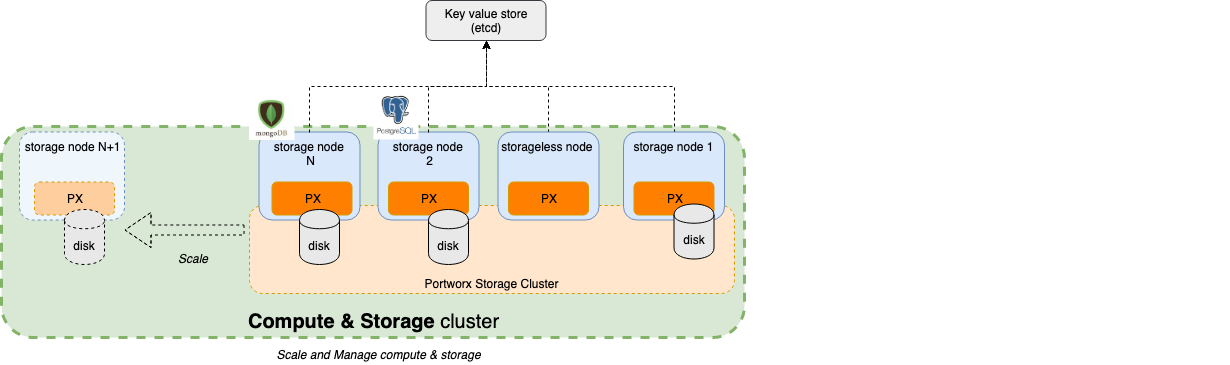
What
- A single cluster with nodes providing storage and compute both (green above). (e.g a single Kubernetes cluster)
- The cluster could have certain nodes that don't have disks. These nodes can still run stateful applications.
- Scaling & managaging operations on this cluster affect both Storage and Compute nodes.
Why
This approach is suitable for clusters that typically have the following characteristics:
- Hyperconveged compute and storage to achieve high performance benchmarks
- The instances in the cluster are mostly static. This means they don't get recycled very frequently.
- Scaling up and scaling down of the cluster is not that frequent
- The cluster admins don't want separation of concern between the Storage and Compute parts of the cluster.