Disaster recovery in GKE
Disaster Recovery (DR) is a process that ensures the availability and recoverability of services and resources within a cluster in the event of a disaster. When you implement a DR strategy provided by Portworx, it mitigates or minimizes data loss caused by unforeseen incidents that can disrupt business operations. The goal is to swiftly restore the operational status of a cluster, enabling access to data as soon as possible after a disaster occurs.
You can easily manage the failover and failback of your applications. Failover is the process of migrating an application or workload from your source cluster to a destination cluster in the event of a failure or disruption in the source cluster. Failback is the process of moving the application and its data back to the source cluster once the source cluster is restored and operational again.
Asynchronous DR
This section describes the asynchronous methods for achieving Disaster Recovery (DR) between multiple clusters when using Portworx.
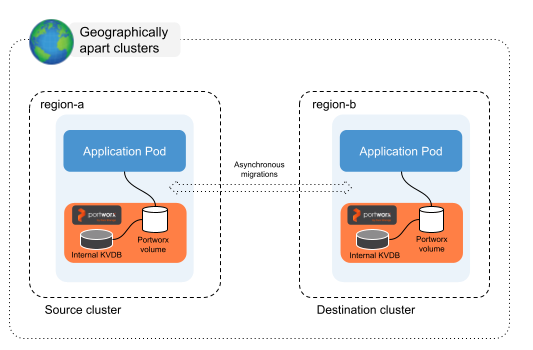
Asynchronous DR involves replicating data from a source cluster to a destination cluster with a delay between the data changes occurring on the source cluster and their replication to the destination cluster.
In an Asynchronous DR setup, a separate Portworx cluster is installed on each Kubernetes cluster. This method can be used in a heterogeneous environment. For volume replications, you need to create migration schedules to migrate applications and volumes between the clusters that are paired.
With this setup, the Recovery Point Objective (RPO) is 15 minutes and the Recovery Time Objective (RTO) is less than 60 seconds.
You should consider this setup when:
- Nodes in all your clusters are in the different regions or datacenter.
- The network latency between the nodes is higher than 10 ms.